Web Scraping Project Gutenberg
There are many data sources on the web that are not available via API but are only available in a human readable website form. This is where web scraping comes in. Web scraping consists of “scraping” or downloading the site, saving data, and following links in an automated fashion.
Let’s take a look at Project Gutenberg:
This site is good and easy practice for web scraping for a few reasons:
- The URL for each book is a simple number that we can increment to scrape each book.
- Inspecting the page shows that the only h1 element on each page is the title.
The first thing that I wanted to do is connect to my database and create a schema to save data to. I wanted to preserve the book’s title, a URL to the plaintext version of the book, and the plaintext version of the book itself:
const mongoose = require("mongoose");
mongoose.connect("mongodb://localhost:27017/books",
{useNewUrlParser: true, useUnifiedTopology: true});
const bookSchema = new mongoose.Schema({
bookTitle: String,
bookUrl: String,
book: String
});
const LibraryModel = mongoose.model("Library", bookSchema);
This connects to my local database called “books”, defines a schema, and then creates a model called Library. This model can be used later to add data to our database.
Next, I made a function called getBook that scrapes a single page and saves the title.
const pageString = "http://www.gutenberg.org/ebooks/"
function getBook(url) {
var title = "";
var newUrl = "";
axios
.get(url)
.then((response) => {
if (response.status === 200) {
let html = response.data;
let $ = cheerio.load(html);
let plainUrl = "";
title = ($("h1").text());
plainUrl = $("[content='text/plain']").children().attr("href");
var newTableEntry = new LibraryModel({
bookTitle: title,
bookUrl: newUrl
})
newTableEntry.save();
}
})
.catch((err) => { return null });
}
getBook(pageString + "1");
This sends a request to http://www.gutenberg.org/ebooks/1 and if the request is successful, searches the page for the data that I need. Saving the book title is easy since there is only a single h1 element on the page. I was able to use Cheerio and jQuery syntax to extract the h1 text to save. Next I need to save the URL for the plaintext version of the book that I need. This is trickier. This searches the page for an element with attribute “text/plain”, grabs the first child of that element, and returns the attribute “href” to save.
Now that both pieces of data are saved they can be pushed into the database. I created a new LibraryModel then saved the data to the database.
I also want the plaintext version of the book though. Inside the axios success block we can insert another call that gets the book itself.
function getBook(url) {
var title = "";
var newUrl = "";
var newBook = "";
axios
.get(url)
.then((response) => {
if (response.status === 200) {
let html = response.data;
let $ = cheerio.load(html);
let plainUrl = "";
title = ($("h1").text());
plainUrl = $("[content='text/plain']").children().attr("href");
newUrl = "http://www.gutenberg.org" + plainUrl;
axios
.get(newUrl)
.then((response) => {
if (response.status === 200) {
let html = response.data;
let $ = cheerio.load(html);
newBook = $.text();
console.log(title);
var newTableEntry = new LibraryModel({
bookTitle: title,
bookUrl: newUrl,
book: newBook })
newTableEntry.save();
}
})
.catch((err) => { return null });
}
})
.catch((err) => { return null });
}
This code grabs a page as before except now it will save the plaintext version of the book. Passing this function a book URL should produce:
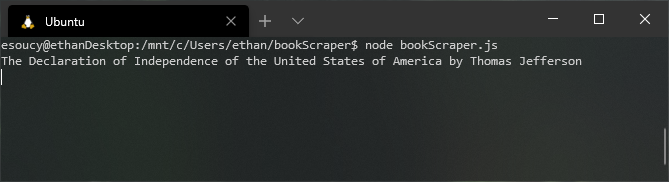
But wouldn’t it be nice to scrape every book that is available in plaintext? Checking Project Gutenberg shows that they have http://www.gutenberg.org/ebooks/1 - http://www.gutenberg.org/ebooks/61610.
Simply feeding these URLs with a for-loop would be bad because of the way Javascript handles asynchronous calls. If we were to run this in a for-loop all 60,000+ requests would be fired off in a few seconds, overwhelming the site, and possibly get your IP address banned. A better way to do this is to limit yourself to slow your requests down to a reasonable amount so as to not degrade the performance of the site you are scraping.
To do this I used Bottleneck. This allows me to use a “limiter” that will trickle my requests out.
const limiter = new bottleneck({
maxConcurrent: 4,
minTime: 250
});
This allows no more than 4 connections at a time and no requests can be made less than 250ms apart.
I then added another parameter to the function that tracks the progress for printing to the console during runtime.
The final code is as follows:
const axios = require("axios");
const cheerio = require("cheerio");
const bottleneck = require("bottleneck");
const limiter = new bottleneck({
maxConcurrent: 4,
minTime: 250
});
// Create database connection
const mongoose = require("mongoose");
mongoose.connect("mongodb://localhost:27017/books", { useNewUrlParser: true, useUnifiedTopology: true });
const pageString = "http://www.gutenberg.org/ebooks/"
const lastBook = 61610;
// Create database schema
const bookSchema = new mongoose.Schema({
bookTitle: String,
bookUrl: String,
book: String
});
const Library = mongoose.model("Library", bookSchema);
function getBook(url, iteration) {
var title = "";
var newUrl = "";
var newBook = "";
// Get book title and URL
axios
.get(url)
.then((response) => {
if (response.status === 200) {
let html = response.data;
let $ = cheerio.load(html);
let plainUrl = "";
title = ($("h1").text());
plainUrl = $("[content='text/plain']").children().attr("href");
newUrl = "http://www.gutenberg.org" + plainUrl;
// Get book
axios
.get(newUrl)
.then((response) => {
if (response.status === 200) {
let html = response.data;
let $ = cheerio.load(html);
newBook = $.text();
// Save information in database and print progress
console.log(iteration + " of " + lastBook + " - " + Math.round(iteration / lastBook * 100) + "%: " + title);
var newTableEntry = new Library({ bookTitle: title, bookUrl: newUrl, book: newBook })
newTableEntry.save();
}
})
.catch((err) => { return null });
}
})
.catch((err) => { return null });
}
for (let i = 1; i <= lastBook; ++i) {
limiter.schedule(() => getBook(pageString + i, i));
}
We shoud now see the following in our terminal when we run the app:

And if we query our database we should see the books:
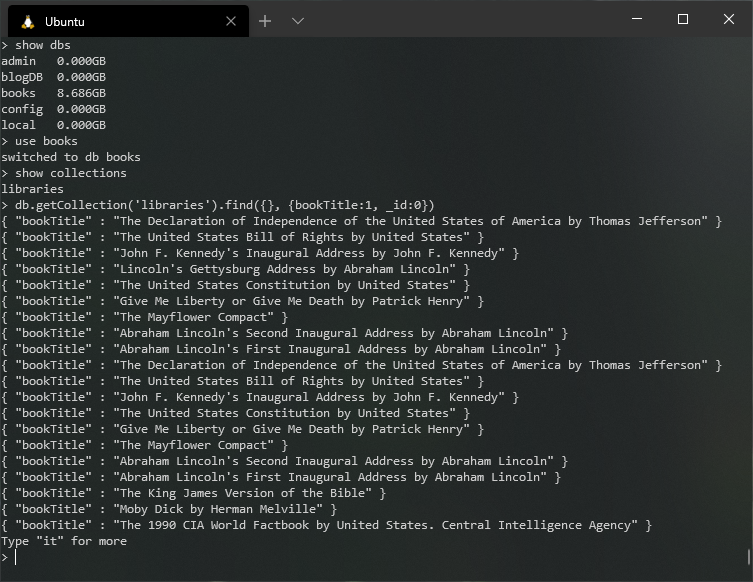
After action:
There are a few things that I could have done better but this was a fun first web scraper.
-
For one, it seems wasteful to leave a site without saving a majority of the information into our database. We should work to minimize the requests we need to make and save as much as we can on every request.
-
The database will duplicate data if the script is re-ran.